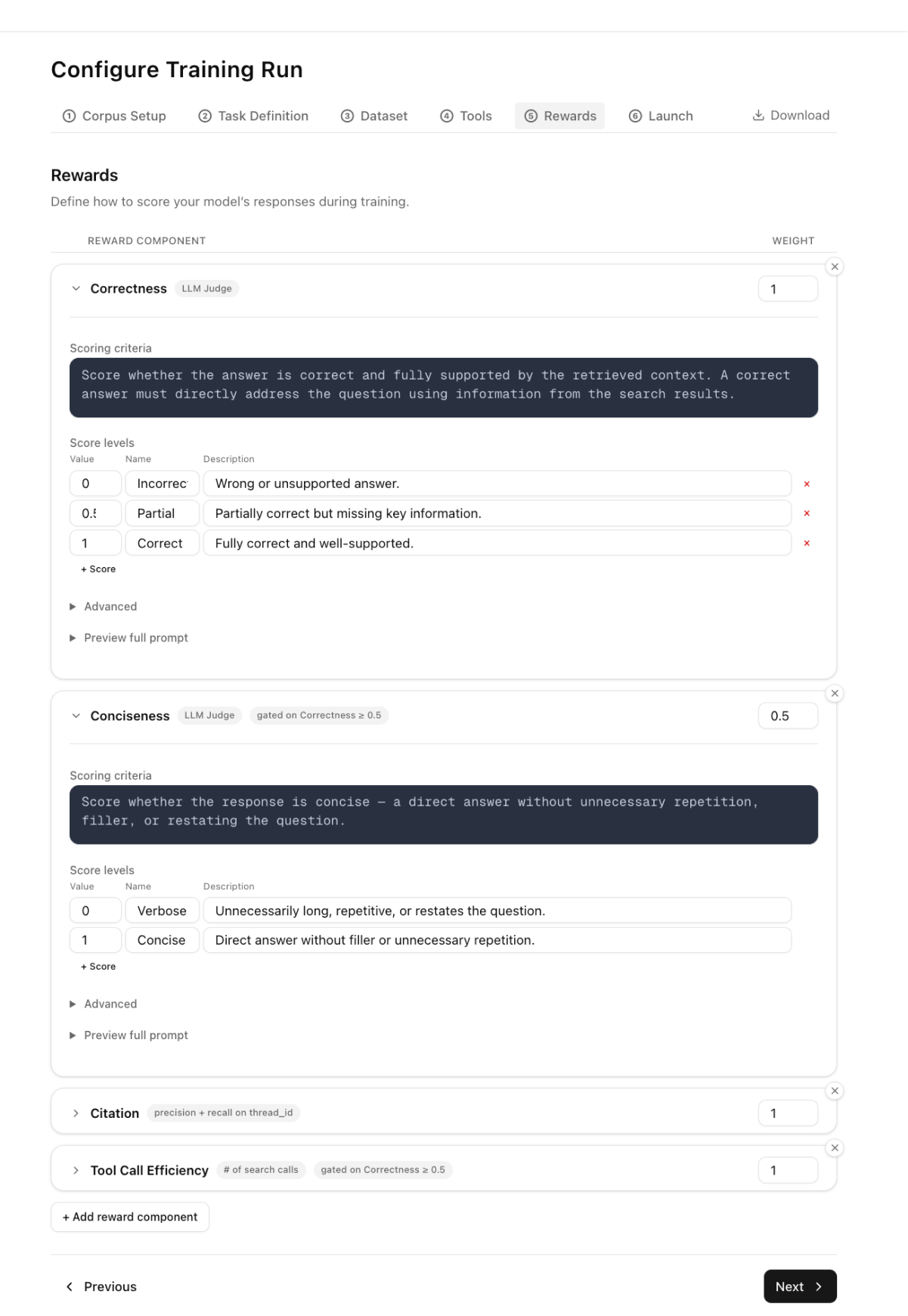
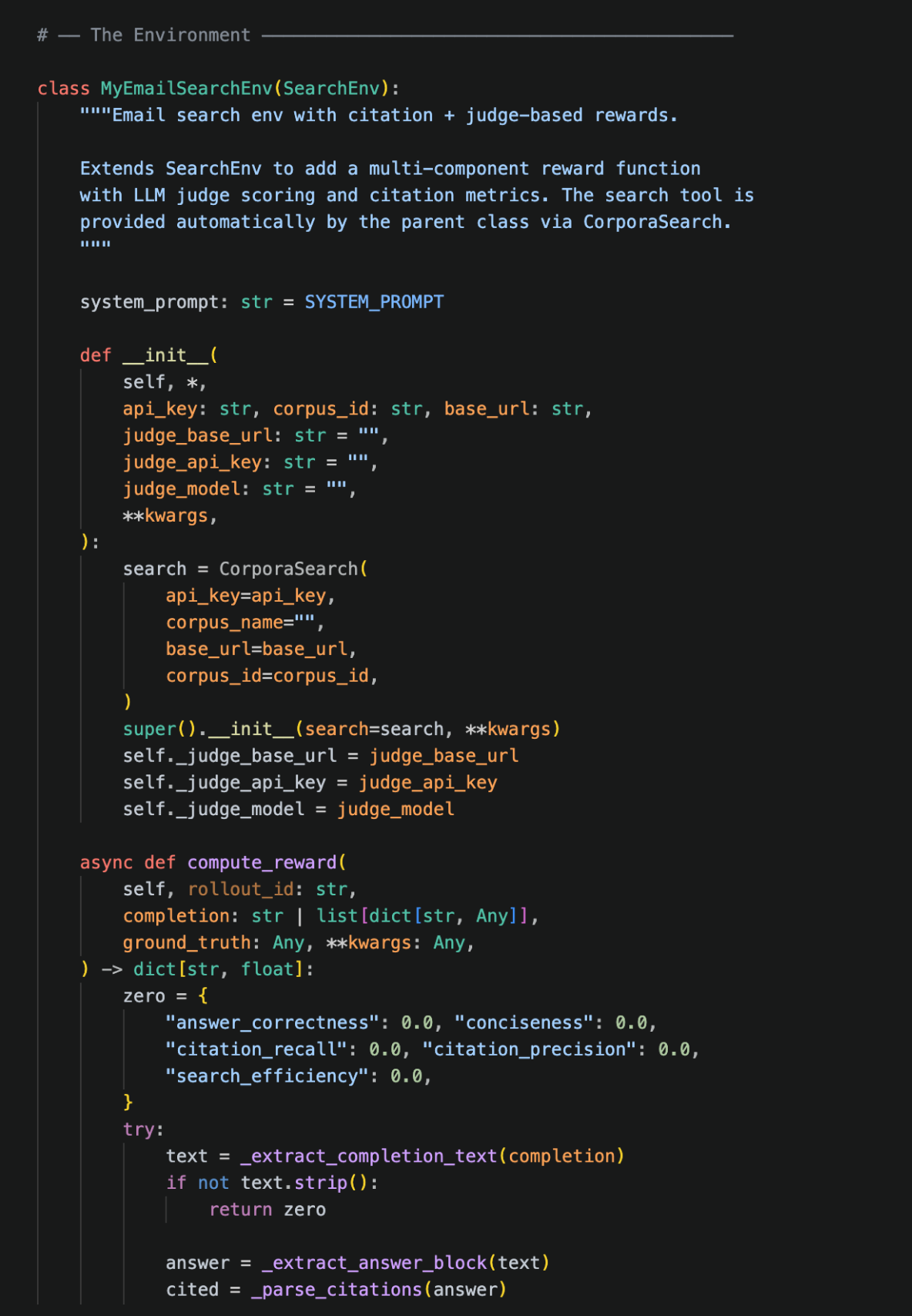
castform is a reinforcement learning finetuning platform that lets you finetune models for specific workloads (rag, agentic tasks, etc.) without having to be an ai expert.
you bring your data and we’ll auto-generate rl environments, build reward signals and eval harnesses, and run the training loop end-to-end. when you want to go deeper, everything is configurable.

we handle the ml and infra complexity so you can focus on the interesting tasks that are specific to your goal:
| you focus on | we handle |
|---|---|
| your data upload yourself or use one of our integrations | data pipeline chunking, indexing, synthetic data from docs or agentic traces |
| success criteria define what “good” looks like for your task | training infrastructure distributed RL on cloud GPUs, scaling, stability |
| review + iterate inspect results, tweak rewards, retrain | training algorithm reward hacking prevention, collapse detection, mode drift guards |
| observability metrics, rollouts, and model health tracking |
two ways to train
you can use our web ui to start training runs in seconds, or use our python sdk for full extensibility.